JDBC(Java Data Base Connectivity Java数据库连接),就是用Java语言来操作数据库.它是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序.
JDBC是接口,而JDBC驱动才是接口的实现,没有驱动无法完成数据库连接!每个数据库厂商都有自己的驱动,用来连接自己公司的数据库。
JDBC
- JDBC的优点
只需用JDBC API写一个程序,就可以向相应数据库发送SQL调用, 不管数据库是Oracle、MySQL等.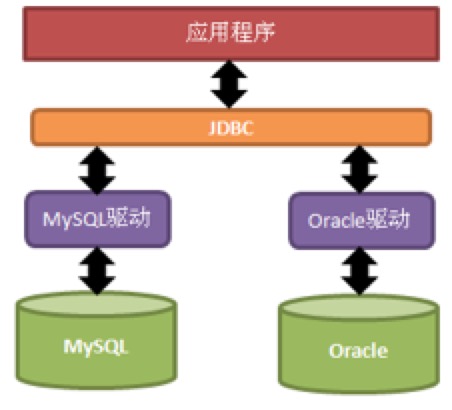
JDBC关系图 - JDBC的作用
- 与数据库建立连接
- 发送sql语句给数据库
- 处理返回数据集
- JDBC API
- java.sql或者javax.sql包下面的
- java.sql.DriverManager: 管理一组 JDBC 驱动程序的基本服务.
- 常用方法
- 注册驱动
public static void registerDriver(Driver driver)- 通过查看
com.mysql.jdbc.driver源码可以看出, 该类中有一个静态代码块进行了驱动的注册, 所有如果使用DriverManager的static方法进行注册会导致两次注册, 所有一般我们很少使用这种方法进行驱动注册., 类被加载进内存时就会执行静态代码块.- 使用反射(常用):
Class.forName(全限定名); - 使用:
类名.class - 使用:
对象.getClass();static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException(“Can’t register driver!”);
}
}
- 使用反射(常用):
- 通过查看
- 注册驱动
- 试图建立到给定数据库 URL 的连接
static Connection getConnection(String url,String user,String password):- url的格式:
协议 : 子协议 : 子名称- MySQL:
jdbc:mysql://localhost:3306/Shopping- 如果我们连接的是本机并且端口号是3306,以上代码也可以简写成
jdbc:mysql:///day06
- 如果我们连接的是本机并且端口号是3306,以上代码也可以简写成
- Oracle:
jdbc:oracle:thin:@localhost:1521@实例
- MySQL:
- 我们有时也会在url后面携带参数
jdbc:mysql://localhost:3306/day06?useUnicode=true&characterEncoding=UTF-8
- url的格式:
- 常用方法
- java.sql.Driver: 驱动接口
- java.sql.Connection: 连接接口
- 常用方法
- 获取语句执行者
Statement createStatement()- 会出现SQL注入问题
- 获取预编译语句执行者
PreparedStatement prepareStatement(Stirng sql); - 获取调用存储过程的语句执行者
CallableStatement prepareCall(String sql) - 收到开启事务
setAutoCommit(boolean autoCommit) - 提交事务
commit(); - 事务回滚
rollback()
- 获取语句执行者
- 常用方法
- java.sql.PreparedStatement语句预执行者
- 常用方法
- 设置参数
setXXX(index, value)index是从1开始的整数- 如 setInt、setString等
- 执行SQL语句
- 查询
- executeQuery(), 返回值类型为
java.sql.ResultSet
- executeQuery(), 返回值类型为
- 更新、删除等
- int executeUpdate(), 返回值为受影响的行数.
- 查询
- 设置参数
- 常用方法
- java.sql.ResultSet: 结果集 接口
- 常用方法
- 判断是否有下一项
boolen next(), 没有则返回false - getXXX(int | String)
- 如果参数为int: 根据第几列获取值(下标从1开始)
- 如果参数为String: 根据 字段名 获取值
- 判断是否有下一项
- 常用方法
- JDBC的一般步骤
- 1、新建Java项目
- 注意要把eclipse设置里面
Preferences—workspace—Text file encoding改为UTF-8. - 尽量使用自己的JDK, 不要使用内置的.
- 注意要把eclipse设置里面
- 2、新建数据库和表
- 3、导入JDBC驱动jar包
- 复制jar包到项目中, 一般将jar包放在一个专门的目录中, 如
lib - 选择导入的jar包—-
右键—-Build Path—-Add to Build Path
- 复制jar包到项目中, 一般将jar包放在一个专门的目录中, 如
- 4、编码
- 1、注册驱动
- MySQL数据库:
Class.forName("com.mysql.jdbc.Driver");
- MySQL数据库:
- 2、获取连接
Connection connection = (Connection) DriverManager.getConnection("jdbc:mysql://localhost:3306/Day07", "root", "123456");"jdbc:数据库类型://host地址:端口号/数据库名称", "用户名", "密码"
- 3、编写SQL语句
String sql = "select * from category;";
- 4、创建预编译的语句执行者
PreparedStatement state = connection.prepareStatement(sql);- Java提供了 Statement、PreparedStatement 和 CallableStatement三种方式来执行查询语句,其中 Statement 用于通用查询, PreparedStatement 用于执行参数化查询,而 CallableStatement则是用于存储过程。
- PreparedStatement是java.sql包下面的一个接口,用来执行SQL语句查询,通过调用connection.preparedStatement(sql)方法可以获得PreparedStatment对象。数据库系统会对sql语句进行预编译处理(如果JDBC驱动支持的话),预处理语句将被预先编译好,这条预编译的sql查询语句能在将来的查询中重用,这样一来,它比Statement对象生成的查询速度更快。
- PreparedStatement优点
- PreparedStatement可以写动态参数化的查询
- PreparedStatement可以防止SQL注入式攻击
- PreparedStatement比 Statement 更快
- PreparedStatement优点
- PreparedStatement是java.sql包下面的一个接口,用来执行SQL语句查询,通过调用connection.preparedStatement(sql)方法可以获得PreparedStatment对象。数据库系统会对sql语句进行预编译处理(如果JDBC驱动支持的话),预处理语句将被预先编译好,这条预编译的sql查询语句能在将来的查询中重用,这样一来,它比Statement对象生成的查询速度更快。
- 5、设置参数
- 如果sql语句中没有参数
?, 不需要设置. state.setXXX(?的index(从1开始), "c005");- 注意: index是从1开始
- 如果sql语句中没有参数
- 6、执行sql(注意:没有参数)
- 执行查询语句返回结果是ResultSet
ResultSet resultSet = state.executeQuery();
- 执行update语句返回结果是受影响的行数
int result = state.executeUpdate();
- 执行查询语句返回结果是ResultSet
- 7、处理结果
while (resultSet.next()) {
System.out.println(resultSet.getString(“cid”) + “:” + resultSet.getString(“name”));
} - 8、释放资源
resultSet.close();
state.close();
connection.close();
- 1、注册驱动
- 1、新建Java项目
- Java中的JUnit单元测试
- JUint单元测试可以在没有main函数的情况下测试
- 方法是public、无返回值、无参数的
- 不能私有构造方法
- 在方法上添加@Test, 没有添加@Test如果使用JUnit Test运行会报错.
- 在@Test上面按
Ctrl(Mac使用Command) + 1或者alt(Mac使用option) + /来导入包import org.junit.Test; - 在方法名上—-
右键—-Run as—-JUint Test—-就可以执行方法了
- 常见配置文件格式
- properties
key=value或key:value形式, 多个键值对使用换行- 可以使用
java.util.Properties类的load(InputStream input)函数读取 - 也可以使用
java.util.ResourceBundle的public static final ResourceBundle getBundle(String baseName)函数获取- 配置文件需要放在src文件夹下
- xml
- properties
- ResourceBundle
- 使用ResourceBundle工具快速获取里面的配置信息, 需要放在src里面
- 常用方法
- 静态方法获取实例:
public static final ResourceBundle getBundle(String 文件名称不带后缀名)ResourceBundle bundle = ResourceBundle.getBundle(“config”);
- 判断是否包含key
public boolean containsKey(String key) - 根据key获取字符串
public final String getString(String key) - 获取所有key(返回的是枚举)
public abstract Enumeration<String> getKeys();
- 静态方法获取实例:
连接池
数据库连接是一种关键的有限的昂贵的资源,这一点在多用户的网页应用程序中体现得尤为突出。对数据库连接的管理能显著影响到整个应用程序的伸缩性和健壮性,影响到程序的性能指标。数据库连接池正是针对这个问题提出来的。
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。
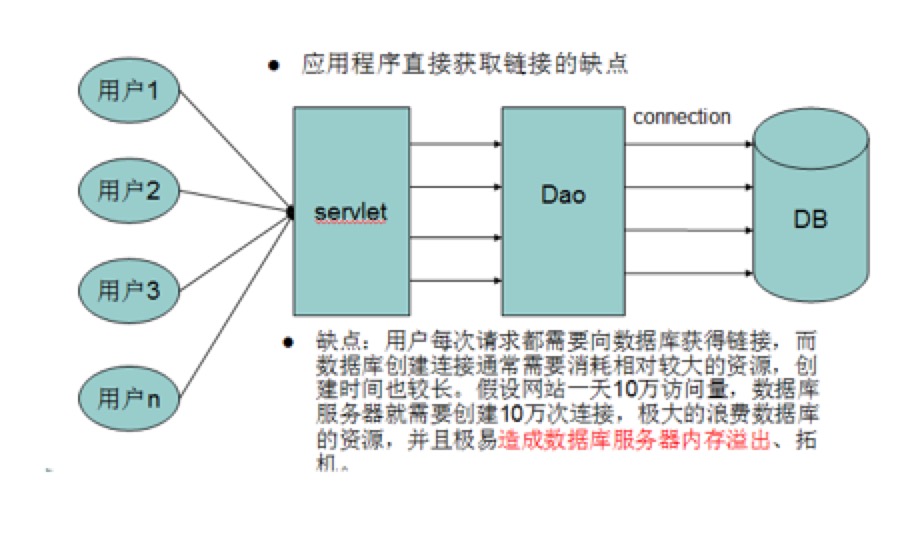
没有连接池
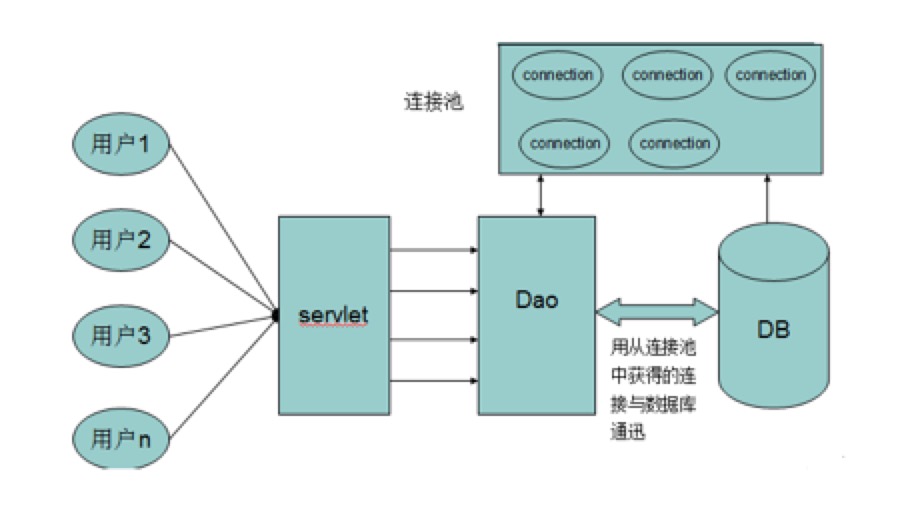
有连接池
- 连接池的优点
- 节省创建连接与释放连接性能消耗
- 连接池中连接起到复用的作用,提高程序性能
- 连接池的原理
连接池基本的思想是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。而连接的建立、断开都由连接池自身来管理。同时,还可以通过设置连接池的参数来控制连接池中的初始连接数、连接的上下限数以及每个连接的最大使用次数、最大空闲时间等等。也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。 - 自定义连接池
- 所有的自定义的连接池必须实现javax.sql.DataSource接口
- 如果连接对象Connection是通过连接池获取的,当通过Connection对象调用close()方法时,不在是销毁连接对象,而是需要将连接对象放回到连接池。
- 使用装饰者模式实现自定义Connection
- 增强的类和被增强的类实现相同的接口.
- 在增强的类中能够获得被增强的类的引用.
- 常用连接池
- DBCP(了解): Apache组织出品
- 使用步骤
- 1、导入jar包 :
commons-dbcp-1.4.jar和commons-pool-1.5.6.jar - 2、使用API
- 2.1 固定的数据库
BasicDataSource bs = new BasicDataSource();
bs.setDriverClassName(“com.mysql.jdbc.Driver”); //设置驱动
bs.setUrl(“jdbc:mysql://localhost:3306/Day07”); //设置数据库连接
bs.setUsername(“root”); //设置用户名
bs.setPassword(“123456”); //设置密码 - 2.2 使用配置文件, 需要添加
driverClassName、url、userName和password的key.
#下面四个是必须配置的//配置文件里面存放
//驱动名称
driverClassName:com.mysql.jdbc.Driver
//数据库连接
url:jdbc:mysql://localhost:3306/Day07
//数据库名称
username:root
//数据库密码
password:123456
#下面的是可配参数
//初始化连接数
initialSize=10
//最大连接数量
maxActive=50
//最大空闲连接
maxIdle=20
//最小空闲连接
minIdle=5
//超时等待时间以毫秒为单位 6000毫秒/1000等于60秒
maxWait=60000
#使用连接池步骤
Properties properties = new Properties();
properties.load(new FileInputStream(“src/properties.properties”));//加载配置文件
DataSource createDataSource = new BasicDataSourceFactory().createDataSource(properties);//创建连接池
- 2.1 固定的数据库
- 1、导入jar包 :
- 使用步骤
- C3P0(★)
C3P0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展。目前使用它的开源项目有Hibernate,Spring等。C3P0具有自动回收空闲连接的功能, 而DBCP不具有自动回收功能.- 使用步骤
- 1、导入jar包 :
c3p0-0.9.1.2.jar - 2、使用API
- 2.1 固定的数据库
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();
comboPooledDataSource.setDriverClass(“com.mysql.jdbc.Driver”);
comboPooledDataSource.setJdbcUrl(“jdbc:mysql://localhost:3306/Day07”);
comboPooledDataSource.setUser(“root”);
comboPooledDataSource.setPassword(“123456”); - 2.2 使用配置文件, 配置文件的名称需要是
c3p0.properties或者c3p0-config.xml, 配置文件需要放在src下面//properties配置文件
c3p0.driverClassName:com.mysql.jdbc.Driver
c3p0.jdbcUrl:jdbc:mysql://localhost:3306/Day07
c3p0.username:root
c3p0.password:123456
//配置好配置文件后, 直接使用下面即可
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();//使用默认配置
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource(“custom”);//自定义配置, 如果没找到会使用默认的
- 2.1 固定的数据库
- 1、导入jar包 :
- 使用步骤
- DBCP(了解): Apache组织出品
- dbutils
dbutils是apache组织的一个工具类, jdbc框架.- 使用步骤
- 1、导入jar包
commons-dbutils-1.4.jar - 2、创建QueryRunner类, 操作SQL语句
- 3、编写SQL语句
- 4、使用QueryRunner对象执行SQL语句
- 4.1、query(…) 执行查询语句
- 4.2、update(…) 支持更新、删除等语句
- 1、导入jar包
- 核心类和接口
- QueryRunner: 用于操作SQL语句
- new QueryRunner(DataSource ds);
- 使用该方法创建的, 会帮我们创建语句执行者、释放资源
* 常用方法 - query(); 执行查询语句
- update(); 执行更新、删除语句
- 使用该方法创建的, 会帮我们创建语句执行者、释放资源
- new QueryRunner(DataSource ds);
- DbUtils: 释放资源、控制事物
- close(): 抛出异常
- queryClose(): 内部处理异常
- ResultSetHandler: 封装结果集, 接口
- 它有9个实现类
- ArrayHandler:将查询结果的第一条封装成数组返回。
- ArrayListHandler:将查询结果的每一条记录封装成数组, 然后将数组放入list中返回。
- BeanHandler(★): 将查询结果的第一条封装成指定Bean对象返回。
- BeanListHandler(★): 将查询结果的每一条封装成Bean对象, 然后放入List中返回。
- ColumnListHandler: 将查询结果的一列放入List中返回。
- MapHandler:将查询结果的第一条记录封装成Map集合返回, 字段名为key, 值为value。
- MapListHandler(★): 将查询结果的每一条记录封装成Map集合, 字段名为key, 值为value, 然后把Map放入List中返回。
- ScalarHandler(★): 针对于聚合函数,
- 它有9个实现类
- QueryRunner: 用于操作SQL语句
- 使用步骤