Lucene和Solr都是基于Java的高效全文检索库.

数据分类
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件
非结构化数据查询方法
- 顺序扫描法(Serial Scanning)
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。 - 全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
全文检索的一般步骤
全文检索大体分两个过程,索引创建 (Indexing) 和搜索索引 (Search) 。
- 索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
- 搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
Lucene
创建索引库
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。
Field域的属性
| Field类 | 数据类型 | Analyzed是否分析 | Indexed是否索引 | Stored是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等)是否存储在文档中用Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue,Store.YES) | Long型 | Y | Y | Y或N | 这个Field用来构建一个Long数字型Field,进行分析和索引,比如(价格) 是否存储在文档中用Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field不分析,不索引,但要Field存储在文档中(如图片,因为要存放图片地址) |
| TextField(FieldName, FieldValue, Store.NO)或TextField(FieldName, reader) | 字符串或流 | Y | Y | Y或N | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
使用的jar包
- Lucene包
- lucene-core-4.10.3.jar
- lucene-analyzers-common-4.10.3.jar
- lucene-queryparser-4.10.3.jar
- 其它
- commons-io-2.4.jar
- junit-4.9.jar
创建索引实例代码
1 | //创建索引 |
查询索引
查询索引也是搜索的过程。搜索就是用户输入关键字,从索引(index)中进行搜索的过程。根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容(这里指磁盘上的文件)。
图形化界面可以使用Luke工具查看索引文件.
IndexSearcher搜索方法
| 方法 | 说明 |
|---|---|
| indexSearcher.search(query, n) | 根据Query搜索,返回评分最高的n条记录 |
| indexSearcher.search(query, filter, n) | 根据Query搜索,添加过滤策略,返回评分最高的n条记录 |
| indexSearcher.search(query, n, sort) | 根据Query搜索,添加排序策略,返回评分最高的n条记录 |
| indexSearcher.search(booleanQuery, filter, n, sort) | 根据Query搜索,添加过滤策略,添加排序策略,返回评分最高的n条记录 |
查询索引实例代码
1 | public class QueryIndex { |
中文分析器
Lucene自带中文分词器
- StandardAnalyzer
- 单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,效果:“我”、“爱”、“中”、“国”。
- CJKAnalyzer
- 二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
- SmartChineseAnalyzer
- 对中文支持较好,但扩展性差,扩展词库,禁用词库和同义词库等不好处理
第三方中文分析器
- paoding
- 已经过时, 停止更新
- mmseg4j
- IK-analyzer
- google代码地址
- 2012年之后停止更新
索引库的维护
索引库的添加
1 | //添加索引 |
索引库删除
删除全部
1 | //删除全部索引 |
指定查询条件删除
1 | //根据查询条件删除索引 |
索引库的修改
原理就是先删除后添加。1
2
3
4
5
6
7
8
9
10
11
12
13
14//修改索引库
public void updateIndex() throws Exception {
IndexWriter indexWriter = getIndexWriter();
//创建一个Document对象
Document document = new Document();
//向document对象中添加域。
//不同的document可以有不同的域,同一个document可以有相同的域。
document.add(new TextField("filename", "要更新的文档", Store.YES));
document.add(new TextField("content", "2013年11月18日 - Lucene 简介 Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。", Store.YES));
indexWriter.updateDocument(new Term("content", "java"), document);
//关闭indexWriter
indexWriter.close();
}
索引库的查询
对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name:lucene”表示查询Field的name为“lucene”的文档信息。
可通过两种方法创建查询对象:
- 1、使用Lucene提供Query子类
- Query是一个抽象类,lucene提供了很多查询对象,比如TermQuery项精确查询,NumericRangeQuery数字范围查询等。
- 如下代码:
- Query query = new TermQuery(new Term(“name”, “lucene”));
- 2、使用QueryParse解析查询表达式
- QueryParse会将用户输入的查询表达式解析成Query对象实例。
- 如下代码:
- QueryParser queryParser = new QueryParser(“name”, new IKAnalyzer());
- Query query = queryParser.parse(“name:lucene”);
使用query的子类查询
TermQuery
TermQuery,通过项查询,TermQuery不使用分析器所以建议匹配不分词的Field域查询,比如订单号、分类ID号等。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//使用Termquery查询
public void testTermQuery() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
//创建查询对象
Query query = new TermQuery(new Term("content", "lucene"));
//执行查询
TopDocs topDocs = indexSearcher.search(query, 10);
//共查询到的document个数
System.out.println("查询结果总数量:" + topDocs.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("filename"));
//System.out.println(document.get("content"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
}
//关闭indexreader
indexSearcher.getIndexReader().close();
}
NumericRangeQuery
可以根据数值范围查询。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//数值范围查询
public void testNumericRangeQuery() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
//创建查询
//参数:
//1.域名
//2.最小值
//3.最大值
//4.是否包含最小值
//5.是否包含最大值
Query query = NumericRangeQuery.newLongRange("size", 1l, 1000l, true, true);
//执行查询
printResult(query, indexSearcher);
}
BooleanQuery
可以组合查询条件。
Occur.MUST:必须满足此条件,相当于and
Occur.SHOULD:应该满足,但是不满足也可以,相当于or
Occur.MUST_NOT:必须不满足。相当于not1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//组合条件查询
public void testBooleanQuery() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
//创建一个布尔查询对象
BooleanQuery query = new BooleanQuery();
//创建第一个查询条件
Query query1 = new TermQuery(new Term("filename", "apache"));
Query query2 = new TermQuery(new Term("content", "apache"));
//组合查询条件
query.add(query1, Occur.MUST);
query.add(query2, Occur.MUST);
//执行查询
printResult(query, indexSearcher);
}
MatchAllDocsQuery
使用MatchAllDocsQuery查询索引目录中的所有文档1
2
3
4
5
6
7
8
public void testMatchAllDocsQuery() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
//创建查询条件
Query query = new MatchAllDocsQuery();
//执行查询
printResult(query, indexSearcher);
}
使用queryparser查询
QueryParser
需要加入queryParser依赖的jar包(lucene-queryparser-4.10.3.jar)1
2
3
4
5
6
7
8
9
10
11
public void testQueryParser() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
//创建queryparser对象
//第一个参数默认搜索的域
//第二个参数就是分析器对象
QueryParser queryParser = new QueryParser("content", new IKAnalyzer());
Query query = queryParser.parse("Lucene是java开发的");
//执行查询
printResult(query, indexSearcher);
}
- 查询语法
- 基础的查询:
域名:关键字- 如:
content:java
- 如:
- 范围查询:
域名+“:”+[最小值 TO 最大值]- 如:
size:[1 TO 1000] - 范围查询在lucene中不支持数值类型,支持字符串类型。在solr中支持数值类型。
- 如:
- 组合条件查询
- +条件1 +条件2: 两个条件之间是并且的关系and
- 如:
+filename:apache +content:apache - 另外一种写法:
条件1 AND 条件2
- 如:
- +条件1 条件2: 必须满足第一个条件,应该满足第二个条件
- 如:
+filename:apache content:apache
- 如:
- 条件1 条件2:两个条件满足其一即可
- 如:
filename:apache content:apache - 另外一种写法:
条件1 OR 条件2
- 如:
- -条件1 条件2:必须不满足条件1,要满足条件2
- 如:
-filename:apache content:apache - 另外一种写法:
条件1 NOT 条件2
- 如:
- +条件1 +条件2: 两个条件之间是并且的关系and
- 基础的查询:
MulitFieldQueryParser
可以指定多个默认搜索域1
2
3
4
5
6
7
8
9
10
11
12
public void testMultiFiledQueryParser() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
//可以指定默认搜索的域是多个
String[] fields = {"filename", "content"};
//创建一个MulitFiledQueryParser对象
MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer());
Query query = queryParser.parse("java and apache");
System.out.println(query);
//执行查询
printResult(query, indexSearcher);
}
Solr
单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
什么是Solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr与Lucene的区别
- Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
- Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
安装Solr
Solr下载地址
Solr解压目录说明
- Solr4.10.3解压目录
- bin: solr的运行脚本
- contrib: solr的一些软件/插件,用于增强solr的功能。
- dist: 该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
- solr-x.x.x.war: 部署到tomcat时拷贝到
tomcat/webapps后运行即可,停掉tomcat之后即可删除tomcat/webapps/solr-x.x.x.war - solr-solrj-x.x.x.jar: Java连接solr服务器使用
- solr-x.x.x.war: 部署到tomcat时拷贝到
- docs: solr的API文档
- example: solr工程的例子目录:
- example/lib/ext: 如果solr需要部署到tomcat, 需要把里面的jar拷贝到
tomcat/webapps/solr/WEB-INF/lib/下 - example/solr: 该目录是一个包含了默认配置信息的Solr-Home目录。
- example/multicore: 该目录包含了在Solr的multicore中设置的多个Core目录。
- example/webapps: 该目录中包括一个solr.war,该war可作为solr的运行实例工程。
- example/lib/ext: 如果solr需要部署到tomcat, 需要把里面的jar拷贝到
- licenses: solr相关的一些许可信息
- Solr5.5.5解压目录
- bin: solr的运行脚本
- contrib: solr的一些软件/插件,用于增强solr的功能。
- dist: 该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
- docs: solr的API文档
- licenses: solr相关的一些许可信息
- server: solr服务
- solr-webapp/webapp: 里面的可以拷贝到Tomcat的webapps中, 部署到tomcat
- server/lib/ext: 里面的jar需要拷贝到tomcat/webapps/solr/WEB-INF/lib下面
- example: solr工程的例子目录
Solr运行环境
Solr需要运行在一个Servlet容器中,Solr4.10.3要求jdk使用1.7以上,Solr默认提供Jetty(java写的Servlet容器),本教程使用Tocmat作为Servlet容器,环境如下:
- Solr: Solr4.10.3
- JDK: JDK1.7.0_72
- Tomcat: apache-tomcat-7.0.53
Solr和Tomcat整合
Solr Home与SolrCore
创建一个Solr home目录,SolrHome是Solr运行的主目录,目录中包括了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore,一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
Solr-4.x.x/example/solr就是一个Solr Home目录结构Solr-4.x.x/example/solr/collection1是一个Solr实例
Solr-4.x.x部署Tomcat
- 1、解压Solr-4.x.x.tar.gz
- 2、将solr解压目录中
solr-4.x.x/dist/solr-4.x.x.war拷贝到tomcat安装目录下/webapps中, 并重命名为solr.war - 3、运行Tomcat, 启动后停止Tomcat, 删除tomcat安装目录下的
/webapps/solr.war - 4、拷贝solr解压目录
solr-4.x.x/example/lib/ext中的的jar包到tomcat安装目录/webapps/solr/WEB-INF/lib/中 - 5、配置Solr home
- 5.1、拷贝solr解压目录
/solr-4.x.x/example/solr拷贝到其他目录中, 可以重新命名, 如/usr/local/solrhome - 5.2、solrhome目录下面可能会有多个solr实例, 每个solr实例文件夹下面的
conf/solrconfig.xml, 可以配置相关的solr配置.
- 5.1、拷贝solr解压目录
6、修改tomcat安装目录下
/webapps/solr/WEB-INF/web.xml1
2
3
4
5<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/usr/local/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>env-entry-name: 名字必须是solr/home, 不能更改env-entry-value: 里面的值就是Solr Home路径
- 7、其他tomcat, 通过
tomcat地址:端口/solr访问
Solr-5.x.x部署Tomcat
Solr-5.x.x最好使用Tomcat8- 1、解压Solr-5.x.x.tar.gz
- 2、将solr解压目录
Solr-5.x.x/server/solr-webapp/webapp拷贝到tomcat安装目录/webapps中, 并改名solr - 3、将solr解压目录
Solr-5.x.x/server/lib/ext中jar包拷贝到tomcat安装目录/webapps/solr/WEB-INF/lib中 - 4、将solr解压目录
Solr-5.x.x/server/resources/log4j.properties拷贝到Tomcat安装目录/webapps/solr/WEB-INF/classes中 - 5、配置Solr Home
- 5.1、新建目录如:
/usr/local/solrhome作为solr home目录, 拷贝solr解压目录/solr-5.x.x/server/solr/solr.xml拷贝到solr home目录中, 拷贝solr解压目录/solr-5.x.x/server/solr/configsets/basic_configs拷贝到solr home目录中并重命名为core, 它是一个实例 - 5.2、solrhome目录下面可能会有多个solr实例, 每个solr实例文件夹下面的
conf/solrconfig.xml, 可以配置相关的solr配置. - 5.3、如果solr管理页面
logging报错:Can't find: admin-xxx.html- 解决方法: 将
/solr-5.x.x/example/example-DIH/solr/solr/conf目录下的admin-extra.xml、admin-extra.menu-bottom.html和admin-extra.menu-top.html拷贝到solr home目录下的solr实例/conf目录即可
- 解决方法: 将
- 5.1、新建目录如:
6、修改tomcat安装目录下
/webapps/solr/WEB-INF/web.xml1
2
3
4
5<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/usr/local/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>env-entry-name: 名字必须是solr/home, 不能更改env-entry-value: 里面的值就是Solr Home路径
- 7、其他tomcat, 通过
tomcat地址:端口/solr/admin.html访问 - 8、如果打开solr管理页面报错solr5.5部署报错:
java.lang.NoSuchMethodError:javax.servlet.ServletInputStream.isFinished()Z, 请使用Tomcat8 - 9、多个solr实例请复制solr home目录中的solr文件夹并重命名为其他名称,并注意修改
core.properties中的name字段为当前solr实例名称.
Solr后台管理页面
一级菜单
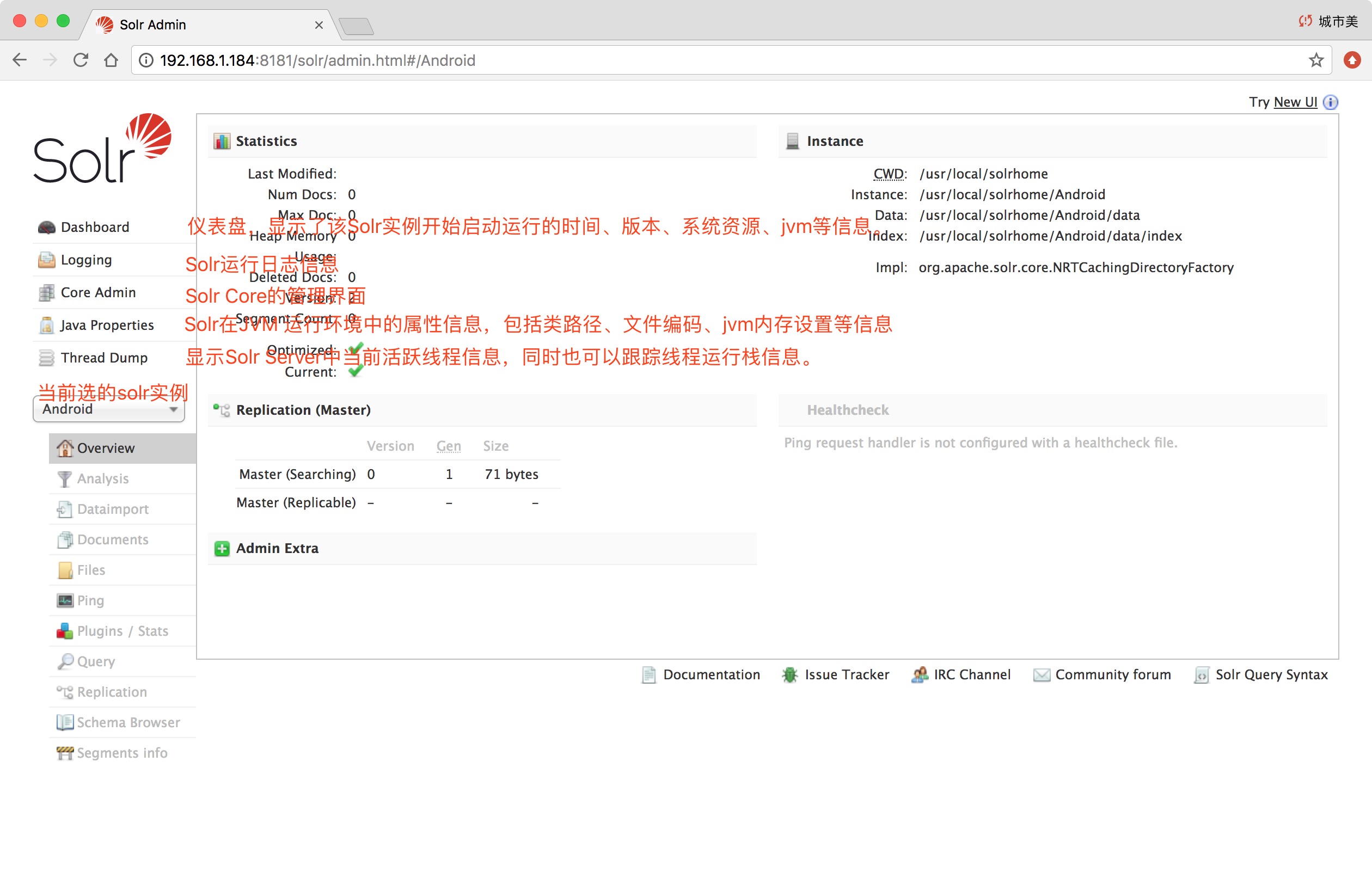
Dashboard: 仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。Logging: Solr运行日志信息Cloud: Cloud即SolrCloud,即Solr云(集群),当使用Solr Cloud模式运行时会显示此菜单Core Admin: Solr Core的管理界面。Solr Core 是Solr的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个Solr工程可以运行多个SolrCore(Solr实例),一个Core对应一个索引目录。java properties: Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。Tread Dump: 显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。Core selector: 可以选择Solr实例Collection Selector: Solr云(集群)版才会显示
二级菜单
通过Core Selector选择一个Solr实例后, 会进入一个二级菜单.
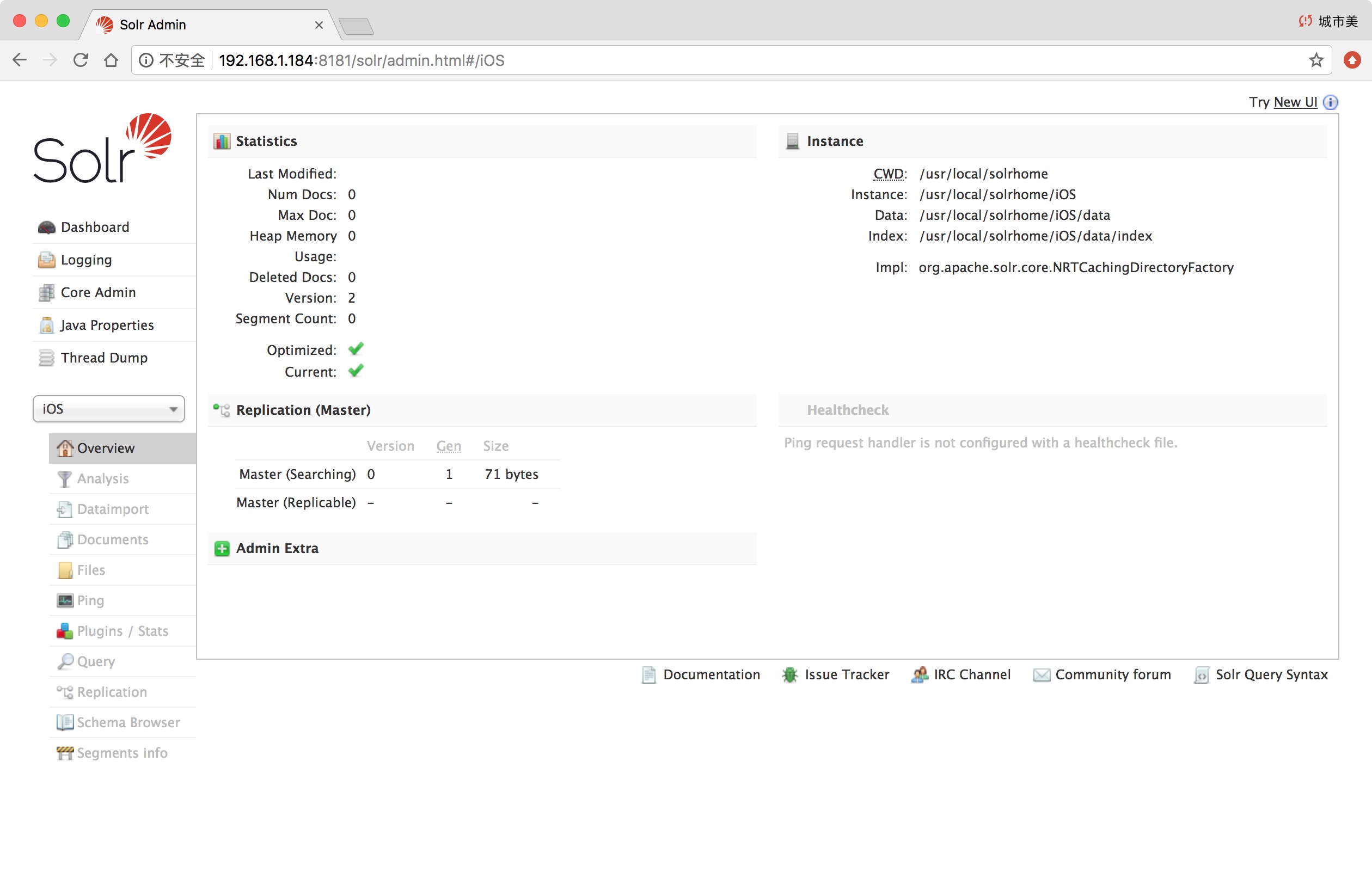
Overview:显示一些统计信息和元数据。Analysis:帮你设计你的Analyzer,Tokenizer和Filter。Dataimport: 展示当前的DataimportHandler的状态,默认是没有。Documents: 提供了一个让你对该solr实例中的数据作增删改操作的表单窗口。Files: 不是指存在solr实例中的业务数据,而是指该solr实例的配置文件,比如solrconfig.xml。Query: 一个简单的结构化查询工具。具体见(Solr页面查询各个参数解释)Ping: 按一下可以看这个solr实例还是不是活着的以及响应时间。Plugins: Solr自带的一些插件以及我们安装的插件的信息以及统计。Replication:显示你当前solr实例的副本,并提供disable/enable功能。Schema: 展示该Core的shema数据,如果是用ManagedSchema模式,还可以通过该页面修改,增加,删除schema的字段。(对比Solr4,是一个比较实用的提升。)Segments info:展示底层Lucence的分段信息。
Solr的使用
自定义FieldType和Field
schema.xml文件,在Solr home目录下面的Solr实例/conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。
- solr-4.x.x, 拷贝的时候会有
schema.xml - solr-5.x.x, 拷贝时里面会有一个
managed-schema.xml文件, 需要改名为schema.xml自定义FieldType
FieldType域类型定义text_general是Solr默认提供的FieldType1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>- name:是这个FieldType的名称
- class:是Solr提供的包solr.TextField,solr.TextField 允许用户通过分析器来定制索引和查询,分析器包括一个分词器(tokenizer)和多个过滤器(filter)
- positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误,此值相当于Lucene的短语查询设置slop值,根据经验设置为100。
- 在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤
- 索引分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,solr.LowerCaseFilterFactory小写过滤器。
- 搜索分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,这里还用到了solr.SynonymFilterFactory同义词过滤器。
自定义Field
在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否存储多个值)等属性。
如下:1
2<field name="name" type="text_general" indexed="true" stored="true"/>
<field name="features" type="text_general" indexed="true" stored="true" multiValued="true"/>
multiValued:该Field如果要存储多个值时设置为true,solr允许一个Field存储多个值.
uniqueKey
Solr中默认定义唯一主键key为id域,如下:1
<uniqueKey>id</uniqueKey>
Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
注意在创建索引时必须指定唯一约束。
copyField复制域
copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索, 下面的例子: 根据关键字只搜索text域的内容就相当于搜索title和content,将title和content复制到text中,如下:
1 | <field name="title" type="text-general" indexed="true" stored="true"/> |
dynamicField(动态字段)
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name 为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
1 | <dynamicField name="*_i" type="int" indexed="true" stored="true"/> |
配置中文解析器
这里我们使用IKAnalyzer分词器.
- 下载地址
- 安装到solr
- 1、将
IKAnalyzer2012FF_u1.jar添加到Tomcat安装目录/webapps/solr/WEB-INF/lib中. - 2、复制IKAnalyzer的配置文件和自定义词典和停用词词典到Tomcat安装目录
/webapps/solr/WEB-INF/classes中. - 3、在Solr Home的目录中的Solr实例的
conf/schema.xml中添加自定义fieldtype1
2
3
4
5
6
7<!-- IK中文分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<!--索引时候的分词器-->
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<!--查询时候的分词器-->
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType> - 4、在Solr Home的目录中的Solr实例的
conf/schema.xml中添加自定义field, 并指定fieldtype是更改定义的fieldtype1
<field name="content" type="text_ik" indexed="true" stored="true" multiValued="true"/>
- 5、重启Tomcat即可
- 1、将
维护索引
单个文档
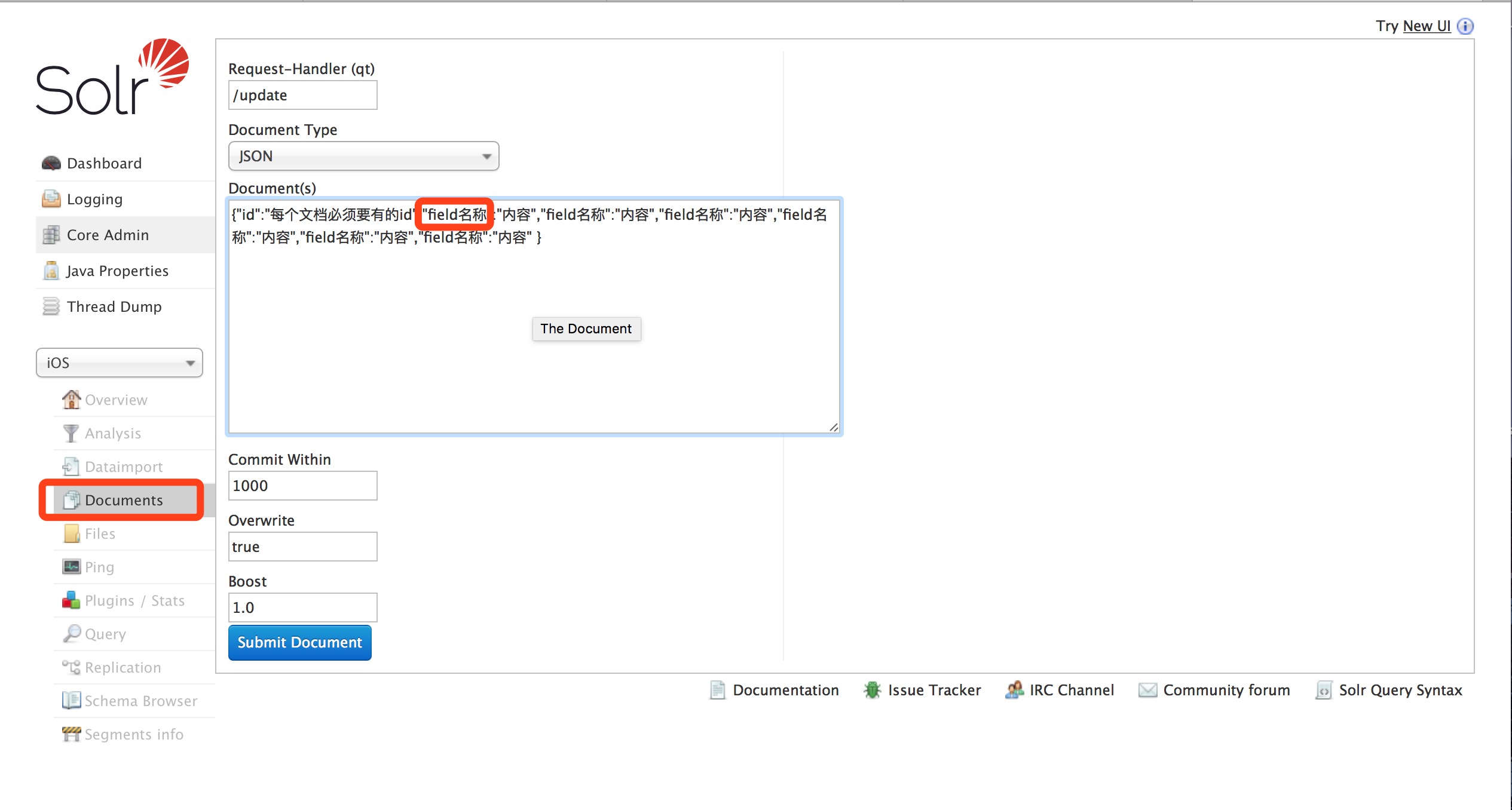
这里的field名称必须是已经在schema.xml中定义的field名称./update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
批量导入数据
使用dataimport插件批量导入数据
- 1、dataimport插件依赖的jar包添加到Solr Home目录中的
solr实例/lib中solr-dataimporthandler-5.5.5.jarsolr-dataimporthandler-extras-5.5.5.jar- 以及数据库连接驱动, 如mysql的java驱动
- 2、在Solr Home目录中的
solr实例/conf中solrconfig.xml, 新增一个requestHandler1
2
3
4
5
6<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler> - 3、创建一个data-config.xml,保存到在Solr Home目录中的
solr实例/conf目录1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/lucene"
user="root"
password="root"/>
<document>
<entity name="product" query="SELECT pid,name,catalog_name,price,description,picture FROM products ">
<field column="pid" name="id"/>
<field column="name" name="product_name"/>
<field column="catalog_name" name="product_catalog_name"/>
<field column="price" name="product_price"/>
<field column="description" name="product_description"/>
<field column="picture" name="product_picture"/>
</entity>
</document>
</dataConfig> - 4、重启Tomcat
- 5、进入Solr管理页面, 选中对应的实例后, 点击
DataImport, 点击Execute即可- 导入数据前会先清空索引库,然后再导入
删除文档
在Documents菜单下, 选择Document Type为XML, Document(s)删除索引格式如下:
- 删除制定ID的索引
1
2
3
4<delete>
<id>8</id>
</delete>
<commit/> - 删除查询到的索引数据
1
2
3
4<delete>
<query>product_catalog_name:幽默杂货</query>
</delete>
<commit/> - 删除所有索引数据
1
2
3
4<delete>
<query>*:*</query>
</delete>
<commit/>
查询索引
通过/select搜索索引,Solr制定一些参数完成不同需求的搜索:
q: 查询字符串
查询字符串: 格式field name:查询的关键字1
2
3
4
5
6#查询单个或者组合查询
field name:需要查询的内容 AND
field name:需要查询的内容 OR
field name:需要查询的内容
#查询所有
*:*
fq: (filter query 过虑查询)
在q查询符合结果中同时是fq查询符合的
1 | #例如 |
sort: 排序
格式: field name desc|asc1
2#如, 商品价格降序
product_price desc
start和rows: 分页和每次返回数量
start: 从0开始
fl: 指定返回那些字段内容,用逗号或空格分隔多个
1 | #如 |
df: 指定一个搜索Field
也可以在Solr Home的Solr实例目录中conf/solrconfig.xml文件中指定默认搜索Field,指定后就可以直接在“q”查询条件中输入关键字。
wt: (writer type)指定输出格式
可以有 xml, json, php, phps等
SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
- 1、集中式的配置信息
- 2、自动容错
- 3、近实时搜索
- 4、查询时自动负载均衡
Solr集群的系统架构
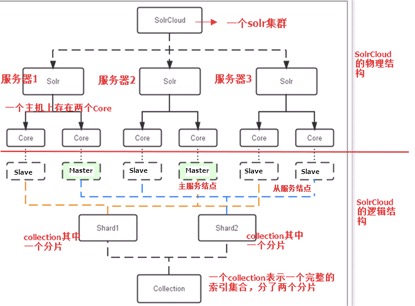
物理结构
三个Solr( 每个Solr包括两个Solr实例),组成一个SolrCloud。
逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
collection
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
Core
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
Master或Slave
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
Shard
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
Solr集群搭建
zookeeper集群
- 在Zookeeper的解压目录中创建
data文件夹 - 在
data文件夹中创建一个文件myid, 内容就是每个实例的id, 例如: 1、2、3等, 不能重复1
echo 1 >> myid
- 更改配置文件名称, 把解压目录中
conf/zoo_sample.cfg改名为zoo.cfg1
mv zoo_sample.cfg zoo.cfg
- 修改配置文件内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/solr-cloud/zookeeper01/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=192.168.1.184:2881:3881
server.2=192.168.1.185:2881:3881
server.3=192.168.1.186:2881:3881dataDir: 修改为新建的data全路径clientPort: 客户端连接Zookeeper的端口- 新增
server.1=192.168.1.184:2881:3881server.1中的1是实例id- IP地址后的第一个端口: Zookeeper内部通讯端口
- IP地址后的第二个端口; zookeeper投票选举端口
- 两个端口和
clientPort不能重复
- 启动每个Zookeeper实例, zookeeper集群搭建完成
1
2
3
4
5
6
7
8
9ZooKeeper JMX enabled by default
Using config: /usr/local/solr-cloud/zookeeper01/bin/../conf/zoo.cfg
Mode: follower
ZooKeeper JMX enabled by default
Using config: /usr/local/solr-cloud/zookeeper02/bin/../conf/zoo.cfg
Mode: leader
ZooKeeper JMX enabled by default
Using config: /usr/local/solr-cloud/zookeeper03/bin/../conf/zoo.cfg
Mode: follower
solrCloud搭建
- 首先在每个solr服务器上安装tomcat, 并部署solr单机版到tomcat, 步骤参考前面
- 更改每个solr home目录下的
solr.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<solrcloud>
<str name="host">192.168.1.184</str>
<int name="hostPort">8080</int>
<str name="hostContext">${hostContext:solr}</str>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<int name="distribUpdateSoTimeout">${distribUpdateSoTimeout:600000}</int>
<int name="distribUpdateConnTimeout">${distribUpdateConnTimeout:60000}</int>
<str name="zkCredentialsProvider">${zkCredentialsProvider:org.apache.solr.common.cloud.DefaultZkCredentialsProvider}</str>
<str name="zkACLProvider">${zkACLProvider:org.apache.solr.common.cloud.DefaultZkACLProvider}</str>
</solrcloud>- 修改host为当前部署的tomcat的ip
- 修改hostport为当前部署的tomcat的端口号
- 让zookeeper统一管理solr配置文件
1
./zkcli.sh -zkhost 192.168.1.184:2181,192.168.1.185:2181,192.168.1.186:2181 -cmd upconfig -confdir /usr/local/solr-cloud/solrhome01/core/conf -confname myconf
- 需要把任意一个Solr Home下面的实例的
conf目录上传到Zookeeper - solr-4.x.x版本可以使用
solr-4.x.x/example/scripts/cloud-scripts/zkcli.sh工具 - solr-5.x.x版本可以使用
solr-5.x.x/server/scripts/cloud-scripts/zkcli.sh工具 - 需要注意的是: 以后配置field都需要在Zookeeper中配置.
- 需要把任意一个Solr Home下面的实例的
- 上传conf完成之后, 验证是否上传成功
- 连接指定Zookeeper:
./zkcli.sh -server ip:port - 运行:
ls /configs - 出现上一步命名的文件夹
myconf即可
- 连接指定Zookeeper:
- 更改每个tomcat目录下的
bin/catalina.sh文件, 关联zookeeper和solr, 添加如下内容:1
JAVA_OPTS="-DzkHost=192.168.1.184:2181,192.168.1.185:2181,192.168.1.185:2181"
- 访问集群
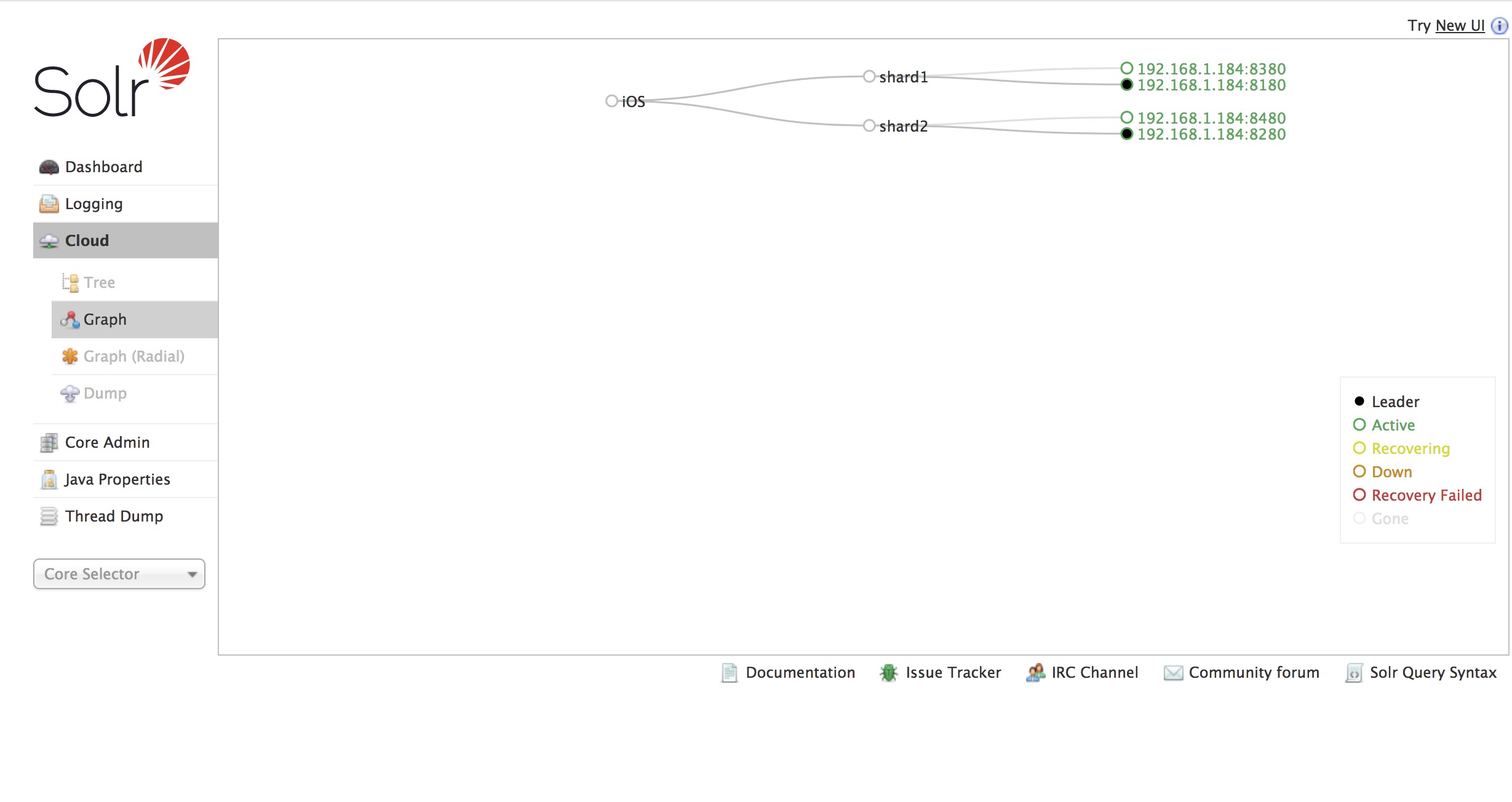
创建新的Collection进行分片处理, 地址栏运行:
1
http://192.168.1.184:8180/solr/admin/collections?action=CREATE&name=xxxx&numShards=2&replicationFactor=2
name为新建的collection名称numShards: 是shard数量
删除不用的Collection, 地址栏运行:
1
http://192.168.1.184:8180/solr/admin/collections?action=DELETE&name=xxxx
name为删除的collection名称- 运行结果如下:
SolrJ
什么是SolrJ
SolrJ是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务
依赖的jar包
- solr-4.x.x版本在解压目录
solr-4.x.x/example/lib/ext中 - solr-5.x.x版本在解压目录
solr-5.x.x/server/lib/ext中单机版和集群版使用区别
单机版和集群版使用有一些区别: - 单机版
- solr4: 使用
HttpSolrServer创建SolrServer对象 - solr5: 使用
HttpSolrClient创建SolrClient对象
- solr4: 使用
- 集群版
- solr4: 使用
CloudSolrServer, 需要指定Zookeeper的地址列表端口和默认collection - solr5: 使用
CloudSolrClient, 需要指定Zookeeper的地址列表端口和默认collection
- solr4: 使用
添加文档
1 | @Test |
- 1、solr4创建一个SolrServer,使用HttpSolrServer创建对象, solr5创建一个SolrCilent,使用HttpSolrClient创建对象。
- 2、创建一个文档对象SolrInputDocument对象。
- 3、向文档中添加域。必须有id域,域的名称必须在
schema.xml中定义。 - 4、把文档添加到索引库中。
- 5、提交。
删除文档
根据id删除
1 | @Test |
- 1、创建一个SolrServer对象。
- 2、调用SolrServer对象的根据id删除的方法。
- 3、提交。
根据查询删除
1
2
3
4
5
6
7@Test
public void deleteDocumentByQuery() throws Exception {
SolrServer solrServer = new HttpSolrServer("http://192.168.1.184:8080/solr/iOS");
//SolrClient solrServer = new HttpSolrClient("http://192.168.1.184:8080/solr/iOS");
solrServer.deleteByQuery("title:change.me");
solrServer.commit();
}查询索引库以及高亮显示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41@Test
public void queryDocument() throws Exception {
//1 Solr4创建一个SolrServer对象, Solr5创建一个SolrClient对象
//SolrClient solrServer = new HttpSolrClient("http://192.168.1.184:8080/solr/iOS");
SolrServer solrServer = new HttpSolrServer("http://192.168.1.184:8080/solr/iOS");
//2 创建一个SolrQuery对象。
SolrQuery query = new SolrQuery();
//3 向SolrQuery中添加查询条件、过滤条件。。。
query.setQuery("*:*");
/*
//开启高亮显示
query.setHighlight(true);
//高亮显示的域
query.addHighlightField("item_title");
query.setHighlightSimplePre("<em>");
query.setHighlightSimplePost("</em>");
*/
//4 执行查询。得到一个Response对象。
QueryResponse response = solrServer.query(query);
//5 取查询结果。
SolrDocumentList solrDocumentList = response.getResults();
System.out.println("查询结果的总记录数:" + solrDocumentList.getNumFound());
//6 遍历结果并打印。
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
/*
//取高亮显示
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
List<String> list = highlighting.get(solrDocument.get("id")).get("item_title");
String itemTitle = null;
if (list != null && list.size() > 0) {
itemTitle = list.get(0);
} else {
itemTitle = (String) solrDocument.get("item_title");
}
System.out.println(itemTitle);
*/
System.out.println(solrDocument.get("item_title"));
System.out.println(solrDocument.get("item_price"));
}
} - 1、创建一个SolrServer对象
- 2、创建一个SolrQuery对象。
- 3、向SolrQuery中添加查询条件、过滤条件。。。
- 4、执行查询。得到一个Response对象。
- 5、取查询结果。
- 6、遍历结果并打印。
SolrJ和Spring整合
新建一个applicationContext-solr.xml, 内容如下:
1 |
|
使用时自动注入:
1 | @Autowired |